使用DeepDanbooru
如何整理自己的图片收藏是令人头疼的问题。目前我倾向于使用标签索引,但接下来头疼的问题就转变为了如何快速准确地给图片打标签。现在我的方式是手工输入,寄希望于整理一定规模之后训练一个专为自己使用的分类模型来自动打标签。
几天前我偶然得知已经有人用Danbooru训练出了类似的模型DeepDanbooru——如此先进生产力,我怎么能不试用下?试用后比较满意,于是就想为己所用。
代码
虽说想要据为己有,但是我压根不懂深度学习,甚至不知道怎样使用训练好的模型。顺着S1的帖子摸索,发现楼主使用了一个叫deepdanbooru-onnx的库。简单扫了一眼那个库,原来总共就没几行代码——这下我有信心了,看起来单纯使用没什么难的么!于是又翻身打开原版的DeepDanbooru浅读了下从evaluate函数开始的代码,发现仅仅使用的话确实很简单:加载模型、缩放图片、居中后补齐短边、reshape、预测、输出就完了。
假设下载好并解压的模型位于model文件夹内,要打标签的图片叫做image.jpg的话,只要运行如下代码就可以获得标签了:
import json
import tensorflow as tf
import numpy as np
from os import path
def load_model_tags(model_path):
with open(path.join(model_path, "project.json")) as f:
project = json.loads(f.read())
with open(path.join(model_path, "tags.txt")) as f:
tags = [tag.strip() for tag in f.readlines()]
model_path = path.join(model_path, f'model-{project["model"]}.h5')
model = tf.keras.models.load_model(model_path, compile=False)
return model, tags
def prepare_image(image_path, input_shape):
image = tf.io.decode_image(
tf.io.read_file(image_path), channels=3, expand_animations=False
)
image = tf.image.resize(
image,
input_shape[1:3],
method=tf.image.ResizeMethod.AREA,
preserve_aspect_ratio=True,
)
image = image.numpy()
pad_width = []
for i in range(2):
diff = input_shape[i + 1] - image.shape[i]
half = diff // 2
pad_width.append((half, diff - half))
pad_width.append((0, 0))
image = np.pad(image, pad_width, "edge")
image /= 255
image = image.reshape((1,) + image.shape)
return image
def evaluate(image, model, tags, threshold=0.5):
prediction = model.predict(image)[0]
res = [
(tag, reliability)
for tag, reliability in zip(tags, prediction)
if reliability > threshold
]
return sorted(res, key=lambda xs: 1 - xs[1])
if __name__ == "__main__":
model, tags = load_model_tags("model")
image = prepare_image("image.jpg", model.input_shape)
for tag, reliability in evaluate(image, model, tags):
print(f"{reliability:.0%}\t{tag}")写这段代码时最让我纠结的地方是prepare_image里缩放和填充那一段。原代码是使用tf.image.resize在保持比例的情况下把最长维度缩小到512像素,然后用skimage.transform.warp把图像居中并把短边用边界值补齐到512像素。我不太想额外依赖scikit-image,但本着输入图片处理方法应该无限接近训练图片的原则,使用NumPy进行了土法居中和补齐(TensorFlow依赖NumPy)。
deepdanbooru-onnx那个库里是直接用Pillow把图片拉伸到512×512,而不是用边界值补齐。其实大差不差——有人画出来就是瘦,有人画出来就是胖。但我还是想要“尊重原著”——无他,只因为我不懂机器学习,害怕用错了。
测试
由于DeepDanbooru是专为二次元图片训练的,所以很遗憾不能用莱娜图做演示。万幸的是,推特上有画师分享了特征明显并且可以再分发的二次元人像。让我们用她看看这DeepDanbooru准不准:

| 标签 | 可靠性 |
|---|---|
| rating:safe | 1.000 |
| 1girl | 0.998 |
| long_hair | 0.974 |
| solo | 0.972 |
| breasts | 0.968 |
| blonde_hair | 0.932 |
| blue_eyes | 0.912 |
| pantyhose | 0.863 |
| looking_at_viewer | 0.854 |
| full_body | 0.836 |
| smile | 0.824 |
| long_sleeves | 0.789 |
| cleavage | 0.769 |
| simple_background | 0.767 |
| white_background | 0.734 |
| large_breasts | 0.710 |
| wide_sleeves | 0.696 |
| standing | 0.675 |
| black_legwear | 0.666 |
| dress | 0.654 |
| closed_mouth | 0.597 |
| hand_up | 0.595 |
| hair_ribbon | 0.574 |
| white_footwear | 0.534 |
| bangs | 0.505 |
我的结论是:够准了。
优化?
我之所以不想直接运行原版和ONNX版的代码,并且在自己的代码里尽量少依赖额外的库,是因为我想在我那性能低下的VPS上跑个类似https://deepdanbooru.donmai.us/的服务。问了下专门研究模型压缩的同学,他说TensorFlow Lite(TF Lite)可以用int8代替fp32从而减少内存消耗。TF Lite还可以剪枝移除冗余权重——通常可以减掉50%——不过剪枝后要重新训练。不久的将来我也许会试一试TF Lite和ONNX,目前还是先在笔记本上跑原版吧。
我那位同学还告诉我之后可以通过迁移学习把用于二次元图片的DeepDanbooru作用在真人图片上。我试了下直接用DeepDanbooru鉴定真人图片,发现虽然标签少了,但准确率仍然很高。想必这是因为Danbooru上有不少用拟真度很高的3D模型渲染的图片。
图形用户界面
我最近想要一个简单又理想的文件管理器,正好先给DeepDanbooru做个界面来试试手。我选择的GUI库叫PySimpleGUI:我是几年前看到同学在GitHub上给它点星时注意到这个库的,不过因为没有写GUI的需求所以没用过。这次看了看PySimpleGUI作者Mike的文档和视频,感觉这位有点像搞传销的传教士——不是贬义啊,只是用来形容他真的特别想帮你学会他的库。
有兴趣的朋友可以花十几分钟看一看Mike介绍PySimpleGUI生态的视频。为了帮助用户使用PySimpleGUI,他写了好多周边程序:包含所有功能的示例、浏览所有文档的程序、在报错时自动打开编辑器标注错误的帮手、帮助不会用GitHub的人提交issue的应用、334个演示代码等等。看到作者这么热情,我已经急不可耐想要尝试下了。
实际使用起来,这个库确实不辱simple之名——看看下面不用学也能懂的代码就知道了。我挺喜欢用二维数组描述布局和主动捕获事件、更新组件的方式。唯一差评的点是表格宽度不能动态控制。不过我对PySimpleGUI的期望是赶紧让我写好文件管理器开始整理我的数字收藏,所以精雕细琢界面什么的还是往后稍稍。
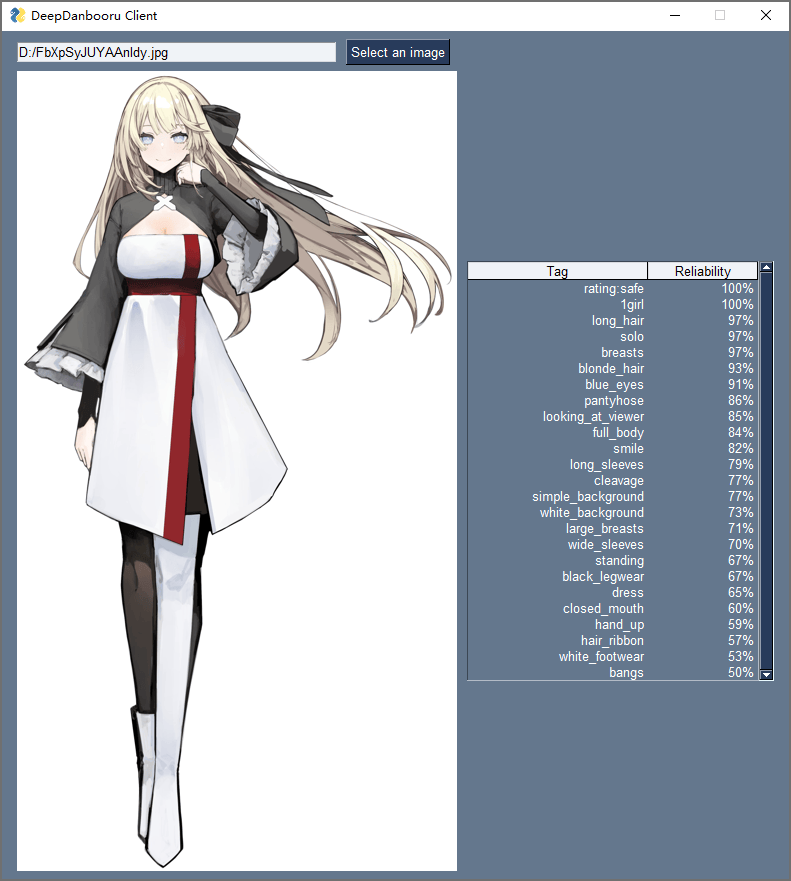
import PySimpleGUI as sg
from PIL import Image, ImageTk, UnidentifiedImageError
from os import path
from ddbr import load_model_tags, prepare_image, evaluate
image_area_size = (800, 800)
layout = [
[
sg.Input(key="-FILENAME-", enable_events=True),
sg.FileBrowse("Select an image"),
],
[
sg.Image(key="-IMAGE-", size=image_area_size),
sg.Table(
key="-TABLE-",
visible=False,
headings=["Tag", "Reliability"],
values=[("eyebrows_visible_through_hair", "84%")],
),
],
]
window = sg.Window("DeepDanbooru Client", layout)
model, tags = load_model_tags("model")
while True:
event, values = window.read()
if event == sg.WIN_CLOSED:
break
elif event == "-FILENAME-":
filename = values["-FILENAME-"]
if path.isfile(filename):
try:
image_display = Image.open(filename)
except UnidentifiedImageError:
sg.popup(f"Can’t open {filename} as an image.")
else:
image_display.thumbnail(image_area_size)
image_display = ImageTk.PhotoImage(image_display)
window["-IMAGE-"].update(data=image_display)
image_evaluate = prepare_image(filename, model.input_shape)
result = evaluate(image_evaluate, model, tags)
result = [(tag, f"{reliability:.0%}") for tag, reliability in result]
window["-TABLE-"].update(
visible=True, values=result, num_rows=len(result)
)
window.close()另外在笔记本上安装TensorFlow时出现了CondaVerificationError,竟然是由于Windows路径长度限制引起的。更令人惊讶的是Windows已经取消了最长限制。
 复制以下链接,并粘贴到你的Mastodon、Misskey或GoToSocial等应用的搜索栏中,即可搜到对应本文的嘟文。对嘟文进行的点赞、转发、评论,都会出现在本文底部。快去试试吧!
复制以下链接,并粘贴到你的Mastodon、Misskey或GoToSocial等应用的搜索栏中,即可搜到对应本文的嘟文。对嘟文进行的点赞、转发、评论,都会出现在本文底部。快去试试吧!