我在一年前用《再见,所有的音乐订阅》记述了自己为什么退订流媒体平台、如何整理音乐收藏。一年过去了,对于“整理音乐收藏”这一话题我仍然兴趣不减,而且有了更多想说的。所以,还是再写一篇吧——我给这两篇都打开了目录,方便各位肉眼diff。

在正式开始之前,请各位先观赏一下我的画作。第一位答出这幅画和本文有什么关系的幸运读者可以找中本聪要十比特币——就说我答应的。
目录
获取音乐文件
我把所有未分类的音乐都放在~/Music/inbox的相应文件夹下。例如,抓轨得到的音乐放在~/Music/inbox/rip中,而从Deezer下载的音乐会放进~/Music/inbox/deemix。下面的整理章节会讲为什么要这样。
CD抓轨
我打算等以后有自己的房子了再买CD自己抓。
我没有忍住,在租房时期就破戒买盘了。我喜欢在手机上听歌,而手机要连光驱比较费劲,所以我需要把CD里的音乐文件抓出来。
2024-02-24注:我发现可以从图书馆借CD。这样既可以避免评论中提出的“CD买多了很沉”的问题,又比较省钱。
Whipper
刚开始我拿放大镜照着碟片抄写过数据,但是读到900多比特眼睛就累得看不清了。所以最后还是得使用软件去抓。那么,应该用哪款软件呢?REDACTED推荐在Windows上使用Exact Audio Copy(EAC),在macOS上使用X Lossless Decoder(XLD)。那Linux呢?他们推荐用Wine模拟Windowss跑EAC。
我在今年夏末又切回了Linux,而且我不打算研究Wine,所以我就得另辟蹊径使用别的软件rip了。最后选择的软件是Whipper——它可以帮助你调整光驱的offset;它可以在MusicBrainz上使用CD的Table of Contents(TOC)来搜索Release id;它会耗尽光驱缓存、多次读取、和AccurateRip的数据库进行比对来确保读出完美的内容。只要设置好光驱、歌曲命名方式,输入whipper cd rip,享受三十分钟光驱痛苦的狞叫,即可得到一份忠实的声音拷贝。
点击查看我的Whipper配置,仅供参考。
[drive:HL-DT-ST%3ADVDRAM%20GP60NS60%20%3ARF01]
vendor = HL-DT-ST
model = DVDRAM GP60NS60
release = RF01
defeats_cache = True
read_offset = 6
[whipper.cd.rip]
prompt = true
output_directory = ~/Music/inbox/rip
# Variables explanations: https://github.com/whipper-team/whipper/issues/283
# track_template is for songs, disc_template is for other files
track_template = %%S/%%d/%%t %%n
disc_template = %%S/%%d/%%A - %%d扫描封面
我有一台朋友送的扫描仪。所以我就不从Cover Art Archive那里下别人扫描的封面了。
平常我使用Skanpage扫描小票、文档之类的。这些东西只要能看出字来就行,所以可以很随意地扫描。但是专辑封面可是艺术品,所以事先查了一些教程。
目前我用Skanpage进行粗略扫描,再用GIMP打开导出的PNG,进行旋转、裁剪、调整色彩、删掉透明通道的修缮工作。我的后处理参考了How to Scan Cover Art,唯一的区别是顺序。
选择扫描PPI其实很简单:使用扫描仪最大的光学分辨率即可(如果有两个数,就是乘号前头的那个)。再往上的设置只会让你的文件更大,观感更糊。

最难的是修复扫描结果的色彩。专业级的扫描仪就像专业级的显示器一样,是要校准的。我的扫描仪是——不能说得太狠,会伤我同学的心,总之,需要后期调整才更接近肉眼看到的样子。出于简单的原因,我采用调整Colour Levels的方式来调整色彩:只需要选出图片中应该为纯黑和纯白的部分,GIMP就会自动帮忙调整所有色彩。
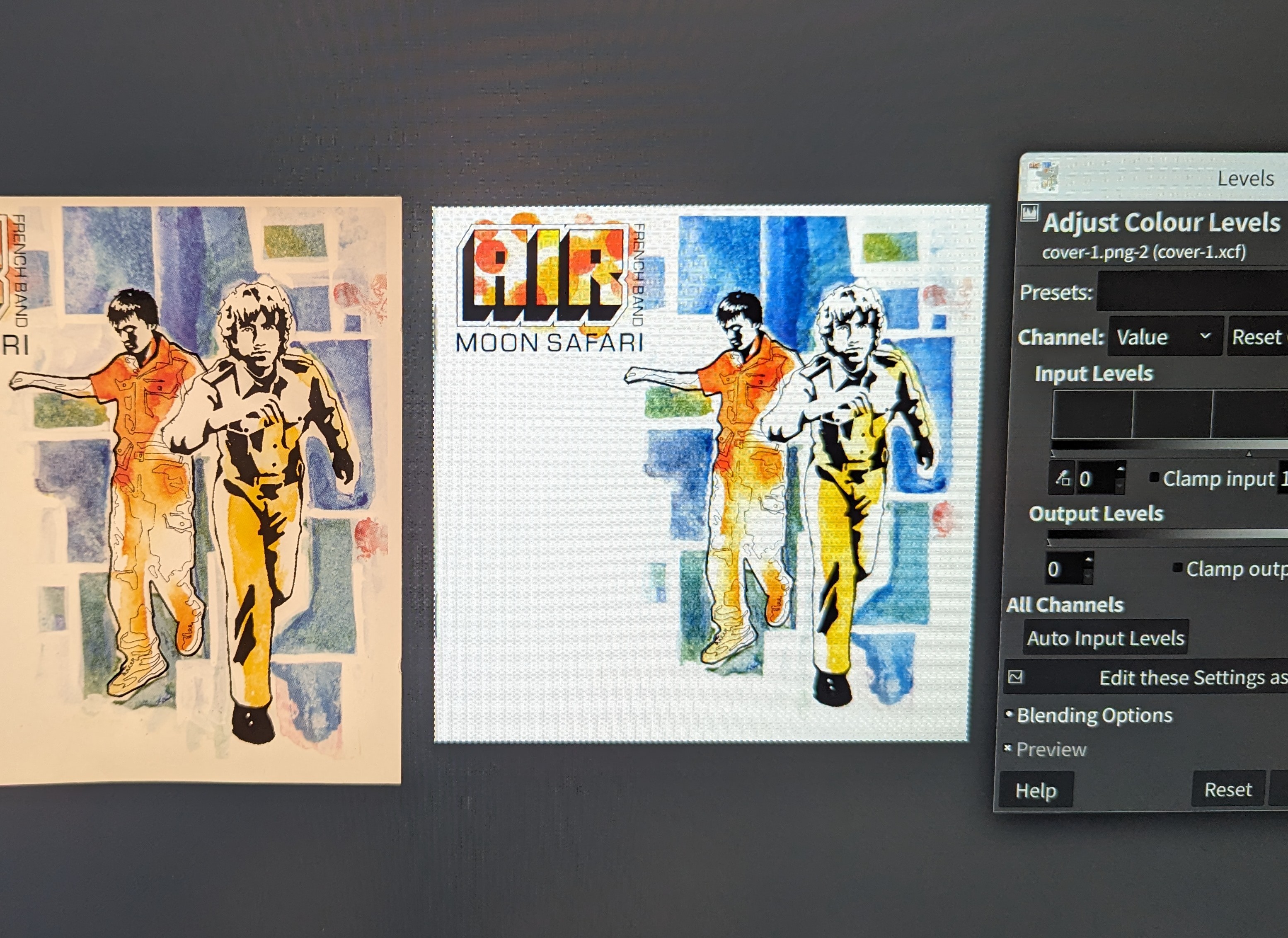
调整Colour Levels后的效果如何?观感上看起来好很多,但是和实物还是没法比。因为自发光的显示器和反射光线的纸无论怎样对比都有天壤之别。所以说,我这台Calman Verified,平均ΔE只有0.3195的显示器白买了。
deemix-py
今年我得知了deemix-py——从云音乐平台Deezer下载无损音乐的工具。坏消息是:deemix-py在一年前就已经停止维护了;好消息是:deemix-py仍然可用,而且是Python写的。所以,即使原作者不再维护了,我也可以在很长的时间内继续使用它。由于deemix-py使用GPLv3许可开源,我也得公开自己的源码:我修改过的deemix-py。
一个听盗版歌的人(是的,rip自己的盘也算盗版)为什么还要遵守软件的许可?其实我也不想听盗版,也不是不想掏钱。但是想要随时随地能听到自己喜欢的音乐,还就只能这么做。让我们听听G胖在11年是怎么说盗版的:
“We think there is a fundamental misconception about piracy. Piracy is almost always a service problem and not a pricing problem,” he said. “If a pirate offers a product anywhere in the world, 24×7, purchasable from the convenience of your personal computer, and the legal provider says the product is region-locked, will come to your country 3 months after the US release, and can only be purchased at a brick and mortar store, then the pirate’s service is more valuable.”
deemix-py使用起来很方便,而且没有难装的依赖。所以除了它的存在以外,我也没什么好介绍的。
Bandcamp
这个网站可以直接给音乐家付费,下载各种格式的音频。不过,它似乎更偏向独立音乐人,所以很少有我想收集的歌。
Nyaa
充满动画歌曲;
注意当地法律。
YouTube
虽然我的大部分音乐已经来自Deezer、CD了,但是仍然有一些曲子只在YouTube上有。相比去年,我添加了下载播放列表/分章节音频的命名方式,并且为了方便整理而重命名、添加了一些元数据。虽然还有一点问题,但用起来已经舒服多了。 因为脚本不是这篇总结的重点,所以被我折叠起来了。点击以查看。#!/usr/bin/env python
from subprocess import run
from sys import argv
from tempfile import TemporaryDirectory
from glob import glob
from mutagen import File
from re import compile
from shutil import copytree
assert len(argv) == 2
def get_cmd(url, dir):
cmd = ['yt-dlp', '-f', 'bestaudio', '--extract-audio', '--add-metadata', '--path', dir, '--output']
if url.startswith("https://www.youtube.com/watch?v="):
# Split by chapters, and delete unsplitted opus
cmd.extend(['%(section_number)d %(chapter_title)s.%(ext)s', "--split-chapters", "--exec", "rm"])
elif url.startswith("https://www.youtube.com/playlist?list="):
cmd.append("%(playlist)s/%(playlist_index)d %(title)s.%(ext)s")
else:
raise RuntimeError("Unsupported URL: " + url)
return cmd + [url]
# TODO not working
date_pattern = compile(r'Released on (\d{4}-\d{2}-\d{2})')
with TemporaryDirectory(prefix='yt-') as dir:
run(get_cmd(argv[1], dir))
for f in glob(f'{dir}/**/*.opus', recursive=True):
assert (audio := File(f)), "Tell Pyright audio isn't None"
# Add source tags
audio['SOURCE'] = 'YouTube'
audio['SOURCEID'] = audio['purl'][0].lstrip('https://www.youtube.com/watch?v=')
# Rename useful tags
audio['ENCODERSETTINGS'] = audio['encoder'][0]
audio['COMMENT'] = (comment := audio['synopsis'][0])
if match := date_pattern.match(comment):
audio['DATE'] = match.group(1)
# Capitalise necessary tags, because that's the standard
for tag in ['language', 'title', 'artist', 'album']:
if tag in audio.keys():
audio[tag.upper()] = audio[tag]
# Remove unecessary tags
for tag in ['language', 'encoder', 'title', 'date', 'purl', 'synopsis', 'artist', 'album']:
if tag in audio.keys():
audio.pop(tag)
audio.save()
# TODO use delete=False after Python 3.12
copytree(dir, new_dir := 'inbox' + dir)
print('Copied to ' + new_dir)
整理
整理方面,我仍然使用Beets。由于上一段开头讲的命名规则,我可以使用 脚本不是这篇总结的重点,所以被我折叠起来了。点击以查看。tree来打印出一个漂亮的树形图(第一层是获取方式,第二层是艺术家名称,第三层是专辑名称),再用fzf选择我想导入哪张专辑。#!/usr/bin/env zsh
inbox=$0:a:h/inbox
IFS=$'\n' albums=(`tree -dlC --noreport $inbox | fzf --tac --ansi --multi`)
setopt EXTENDED_GLOB
full_dirs=()
for album ($albums)
full_dirs+=($inbox/***/${album#*── })
beet import $full_dirs
rm -r $inbox/***/(/DN^F)
蠢货附件:把音乐、图片和数据库都放进蠢货里
是剑桥词典把Git翻译成蠢货的,并不是我想骂人。谢谢大家理解。
我害怕一切不是纯文本的数据,所以对于SQLite3文件一直心存恐惧。而Beets使用SQLite3来记录音乐的元数据,这让我每次使用都提心吊胆。如果我可以记录beets.sqlite3的状态,在出问题时回滚就好了。某些支持快照的文件系统可以做到这点,SQLite3也有自己的导入导出工具,但是我最熟悉的“穿越时间”的工具还是Git。
问题是Git的定位是源码版本控制,它只擅长记录纯文本。不过,我可以使用git-annex,来把大二进制文件在commit时替换成一段指向.git/annex文件夹的哈希值。由git-annex来管理、传送这些大文件,就可以使用Git无感地管理beets.sqlite3了。
使用Git配合git-annex来管理整个音乐文件夹的好处多多。比如可以使用git log列出添加音乐的历史;使用preferred content把音乐自动移动到VPS里来释放笔记本的空间(exclude=**/*.flac and exclude=**/*.opus);使用receive.denyCurrentBranch = updateInstead直接把整个工作目录push到VPS上,以配合Navidrome串流……
另外,我使用Nix flakes和direnv来管理整理音乐需要的Beets、Whipper、yt-dlp等软件。这样的好处是可以把flake.nix和flake.lock也纳入版本控制之中,让整个音乐收藏从软件到数据全都可以回溯。
甜菜:配置文件超进化
这篇文章最开始的内容其实就是这一段:介绍下我的Beets配置文件。一方面,似乎大家更喜欢使用Picard,所以我帮Beets宣传一下;另一方面,我也想记录一下为什么我的配置这么写——然后就写了前面那么多铺垫。 点我看整个文件(下面会按功能分解讲解)。directory: ~/Music
library: ~/Music/beets.sqlite3
plugins:
- fromfilename
- fetchart
- lastgenre
- edit
- missing
- filetote
- zero
- yearfixer
- summarize
- the
- inline
- hook
- rewrite
- info
import:
timid: yes
move: yes
duplicate_action: remove
musicbrainz:
extra_tags: [year, media, country, label]
genres: yes
match:
max_rec:
year: strong
preferred:
countries: ['GB', 'XE']
media: ['Digital Media', 'CD']
ignored_media: ['Vinyl', '12" Vinyl']
hook:
hooks:
- event: import_begin
command: git annex unlock beets.sqlite3
- event: cli_exit
command: git annex add beets.sqlite3
rewrite:
artist Sunset Rollercoaster: 落日飞车
artist The Who & Isobel Griffiths Orchestra: The Who
artist 牛尾憲輔: 牛尾宪辅
fetchart:
source:
- filesystem
per_disc_numbering: yes
album_fields:
multidisc: disctotal > 1
item_fields:
file_src: |
path_str = path.decode().lower()
for source in ["deemix", "rip", "bandcamp", "yt", "nyaa"]:
if source in path_str:
return source
return "other"
paths:
default: $file_src/%the{$albumartist}/%the{$album}%aunique{}/%if{$multidisc,$disc-}$track $title
comp: $file_src/Various Artists/%the{$album}%aunique{}/%if{$multidisc,$disc-}$track $title
lastgenre:
force: no
filetote:
extensions: .toc .cue .m3u .log
pairing:
enabled: true
extensions: .lrc
print_ignored: true
zero:
fields:
# Remove the acoustid metadata
- acoustid_fingerprint
- acoustid_id
update_database: true
Zola的YAML高亮好像有些问题,请大家多担待。
设置目录
为了方便使用Git管理,我把Beets的数据库也放到~/Music里了。
directory: ~/Music
library: ~/Music/beets.sqlite3hooks
由于我使用了git-annex以locked files形式来管理二进制文件,所以我得在Beets修改数据库之前解锁数据库。
hook:
hooks:
- event: import_begin
command: git annex unlock beets.sqlite3
- event: cli_exit
command: git annex add beets.sqlite3实事求是,不自以为是
如果某张专辑(一个release group)有多个版本(多个release),Beets会帮你挑一个看起来像的。这里问题大了,因为默认情况下Beets只会使用音乐家名、专辑名和音轨数查阅MusicBrainz,你需要手动指定musicbrainz.extra_tags才可以用更多的元数据去搜索。
还有一个相关的选项是match:
match.max_rec可以设置如果某个release的这项元数据与你要导入的文件不同,会受到多大的处罚;match.preferred可以设置你更希望某项元数据是什么值的release排在前面。match.preferred.ignored_media可以排除某些介质——但貌似不是每回都起作用。
import:
timid: yes
move: yes
duplicate_action: remove
musicbrainz:
extra_tags: [year, media, country, label]
match:
max_rec:
year: strong
preferred:
countries: ['GB', 'XE']
media: ['Digital Media', 'CD']
ignored_media: ['Vinyl', '12" Vinyl']这些都比不了开启谨小慎微模式的import.timid: yes。只要设置了它,Beets在自作主张之前都会问你,而你可以直接输入你想要的release id(不过MusicBrainz里media是Digital Media的release相对较少,所以大部分情况下不需要手动输id)。
还有一个加强Beets搜索功能的插件,叫beets-originquery。它期望你在待导入专辑目录里写一个记录了正确元数据的txt/JSON。但我还是觉得不如直接在MusicBrainz找到想要的release id,复制到Beets那里方便。
自定义音乐路径
Beets的默认路径是艺术家/专辑名/音轨序号 标题.扩展名的形式(例如:Radiohead/OK Computer OKNOTOK 1997 2017/01 Airbag.flac)。多盘专辑的序号是累计的(比如:Radiohead/OK Computer OKNOTOK 1997 2017/13 I Promise.flac)。
我不喜欢它累计序号的命名方式,所以自定义了Disc xx文件夹来细分每张盘的内容(变成Radiohead/OK Computer OKNOTOK 1997 2017/Disc 02/01 I Promise.flac)。但是这样有两个问题:
- Beets会在导入时随机把封面图片放进某张盘的文件夹里,而我想让封面出现在专辑文件夹;
- 我的播放器期望封面和音乐文件在一个文件夹,它不会检查父文件夹里面有没有封面。
所以,我只能退而求其次,把所有盘的歌曲都放在同一文件夹,使用“盘号-盘内序号”的前缀来命名——忘了说,这个命名只是文件名而已,播放器会根据FLAC的DISCNUMBER、TRACK元数据排序。所以如果不关心播放器背后的文件的话,可以不用管这事。
per_disc_numbering: yes
album_fields:
multidisc: disctotal > 1
item_fields:
file_src: |
path_str = path.decode().lower()
for source in ["deemix", "rip", "bandcamp", "yt", "nyaa"]:
if source in path_str:
return source
return "other"
paths:
default: $file_src/%the{$albumartist}/%the{$album}%aunique{}/%if{$multidisc,$disc-}$track $title
comp: $file_src/Various Artists/%the{$album}%aunique{}/%if{$multidisc,$disc-}$track $title除去用于多盘专辑命名的per_disc_numbering和album_fields.multidisc,我还设置了用于标注歌曲来源的item_fields.file_src。在导入之前,我已经按来源放在inbox文件夹里了,所以这里只是根据导入前的路径复制一下文件夹名称。这样,我从Deezer下载的《OK Computer OKNOTOK 1997 2017》就会被放入deemix/Radiohead/OK Computer OKNOTOK 1997 2017,自己rip的Moon Safari则会被安置在rip/Air/Moon Safari中。
Beets这点很好,让我想起了古罗马教育家昆体良的话:
Calibre作为电子书管理软件有很多值得我们赞许的地方,甚至也有很多值得我们钦佩的地方。要是能让我们自定义电子书在库中的命名方式就好了。
规范音乐家的名称/把多位音乐家记录成一位
rewrite选项可以把音乐家嵌入在音乐文件中的名字转换成自己期望的名字。比如把日文汉字名换成中文汉字名。
rewrite:
artist Sunset Rollercoaster: 落日飞车
artist The Who & Isobel Griffiths Orchestra: The Who
artist 牛尾憲輔: 牛尾宪辅它还可以把多个艺术家的名称替换成一位。其实正确的做法应该是:
- 在FLAC中,使用多个ARTIST元数据(FLAC的每个元数据都可以有多个值);
- 在MP3中,使用NUL字符(␀)分隔音乐家。
但是Beets选择了简单方案:甭管用什么字符分隔,把所有人都当成一位艺术家来记录(这就是为什么我曾经有一个文件夹叫蔡琴, 余天, 蘇芮, 潘越雲, 甄妮, 李建復, 林慧萍, 王芷蕾, 黃鶯鶯, 洪榮宏, 陳淑樺, 娃娃, 王夢麟, 李珮菁, 費玉清, 齊豫, 鄭怡, 江蕙 & 楊林)。热心网友在4743号Pull Request中添加了artists等元数据,但我还是觉得直接rewrite更方便些。
导入非音乐文件
Beets只会在导入专辑时移走专辑封面和音乐文件。如果想保留其他辅助文件——比如rip的log——则需要借助插件来达成目标。目前用于移动非音乐文件,且仍在维护的插件是beets-filetote。使用如下配置即可在导入时保留toc、cue、m3u、log文件,以及和歌曲文件同名的lrc歌词。它还可以打印落下的文件——一般来说是Beets本体会负责的cover.jpg。
filetote:
extensions: .toc .cue .m3u .log
pairing:
enabled: true
extensions: .lrc
print_ignored: true说到歌词,其实我没怎么特意整理歌词,因为我的播放器对歌词的支持很差。但是,我个人认为歌词不应该和音乐分成两个文件,所以我会把带时间戳的歌词写入LYRICS标签,把不带的歌词写入UNSYNCEDLYRICS。
还有,我不认同把封面嵌入歌曲文件的做法——封面是整张专辑的属性,应该放在专辑所在的文件夹里。
音乐脑滋:还是自动挡的车好开
MusicBrainz是一个超大的音乐数据库:从一张专辑在不同地区发行的release,到每首歌曲的engineer、lyricist都是谁……你能想到的信息它统统都有(有位置让你填)。这个数据库对我来说尤其重要,因为Whipper、Beets都是靠它来补全专辑信息的。
我在去年曾简单介绍过如何手动编辑MusicBrainz条目,但是今年我不再一个框一个框地填了——因为我发现了自动化的方法。在我翻MusicBrainz上的编辑记录时,发现很多模板生成的编辑记录,如:
https://atisket.pulsewidth.org.uk/?cached=652637…
with data from the Deezer + Spotify + iTunes APIs
== Vendor links ==
https://www.deezer.com/album/10966642
https://open.spotify.com/album/2IOkphZwsrRk1nWRk…
https://music.apple.com/gb/album/1027461699
== Vendor API links ==
https://api.deezer.com/album/10966642
https://api.spotify.com/v1/albums/2IOkphZwsrRk1n…
Cached: https://atisket.pulsewidth.org.uk/cached/spotify…
https://itunes.apple.com/gb/lookup?id=1027461699…出于好奇,我点开了https://atisket.pulsewidth.org.uk/,从此再也不用开手动挡汽车了。这个网站会帮你收集Deezer、Spotify和iTunes上同一个Universal Product Code(UPC)的专辑,然后填好音乐家、专辑名、唱片公司、发行地区等信息。你需要做的仅仅是确认一下即可。
自从用了它,我导Deezer专辑的速度飞快。
播放
去年促使我整理自己音乐收藏的Navidrome服役到了今年。不过,其实写完那篇博文没多久我就开始用Ultrasonic在手机上听歌了(Ultrasonic可以使用Subsonic协议连通多个Navidrome实例)。总体来说,Ultrasonic界面简洁,功能够用,被我一直用到现在。

今年还试过一款叫Symfonium的Subsonic客户端。它功能更强,界面更——不能说更好看,只能说更精致。鉴于Ultrasonic开源,Symfonium闭源,我最后还是选择了Ultrasonic。
Bonus Track:2023的音乐统计
仿照上一篇,在末尾我也想谈一谈2023年的音乐统计。23年一整年我都在用ListenBrainz统计我的音乐收听记录,大家可以直接访问ListenBrainz为我生成的年终报告。
我从大概十月开始陷入my bloody valentine(下称mbv)无法自拔,所以在年度报告中看到自己23年听得最多的专辑竟然是《The Stone Roses》时,还是有些惊讶的。这张专辑是22年使用苹果音乐时听得第五多的——让我们恭喜这支乐队勇夺殊荣。
22年苹果音乐播放次数最多的专辑是《The Soft Machine》,共102次;23年的《The Stone Roses》是268次。我不清楚两家的计数方式是否一致,所以不评价。
可以比较的是总播放的小时数:22年在苹果音乐上是“1,753首歌,共19,786分钟——相当于13.7天”;23年在ListenBrainz是“10894首歌,至少一个月”。播放数量暴涨的原因可能是整理了自己的音乐库之后,不再用YouTube听歌了,所以有记录的播放增加了。
风格方面:排名前五仍然有硬摇滚和另类摇滚——不过我仍然闹不清区别。排名第五的经典摇滚是什么?抱歉呐,我也不懂。不过,我倒是很懂排名第四的prog rock是什么——用Mellotron的就是prog rock。


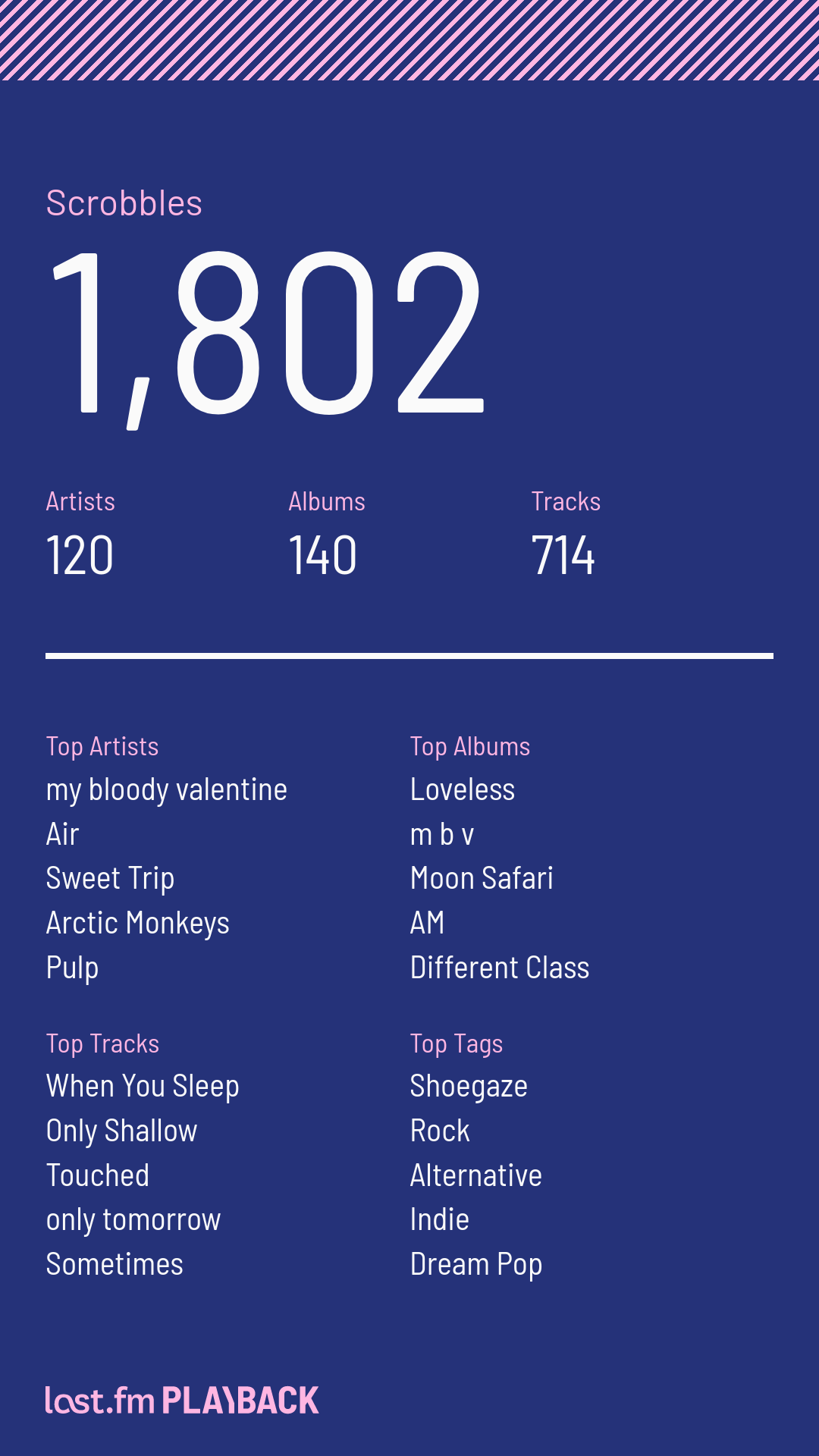
大概十月份时,我又创建了last.fm账号。所以22年我还得到了一份不完整的年度报告——这个报告倒是和我的记忆相符:沉迷mbv不可自拔:排名第一的艺人是mbv,播放数前五的歌曲都来自mbv,播放数前二的专辑也来自mbv,播放最多的音乐分类也是近乎由mbv定义的盯鞋。
因为本小节只是年度音乐统计,所以关于mbv的事情先就此打住。

B-side:停更预告
我目前有九篇文章草稿、四期未发布的电台。我对“完成”有些许执念,也许会在将来把它们完成并发上来。但是,不会再有真正的新内容了。
