目录
实验目的和内容
本实验的目的是了解工业界常用的编译器GCC和LLVM,熟悉编译器的安装和使用过程,观察编译器工作过程中生成的中间文件的格式和内容,了解编译器的优化效果,为编译器的学习和构造奠定基础。
本实验主要的内容为在Linux平台上安装和运行工业界常用的编译器GCC和LLVM,编写简单的测试程序,使用编译器编译,并观察中间输出结果。
实现的具体过程和步骤
- 编译器安装
- 编写测试程序
- 运行编译器进行观测
GCC 运行结果分析
查看编译器的版本
❯ gcc --version gcc (GCC) 9.2.0 Copyright © 2019 Free Software Foundation, Inc. 本程序是自由软件;请参看源代码的版权声明。本软件没有任何担保; 包括没有适销性和某一专用目的下的适用性担保。使用编译器编译单个文件
gcc test.c默认输出a.out,加-o可以指定文件名
使用编译器编译链接多个文件
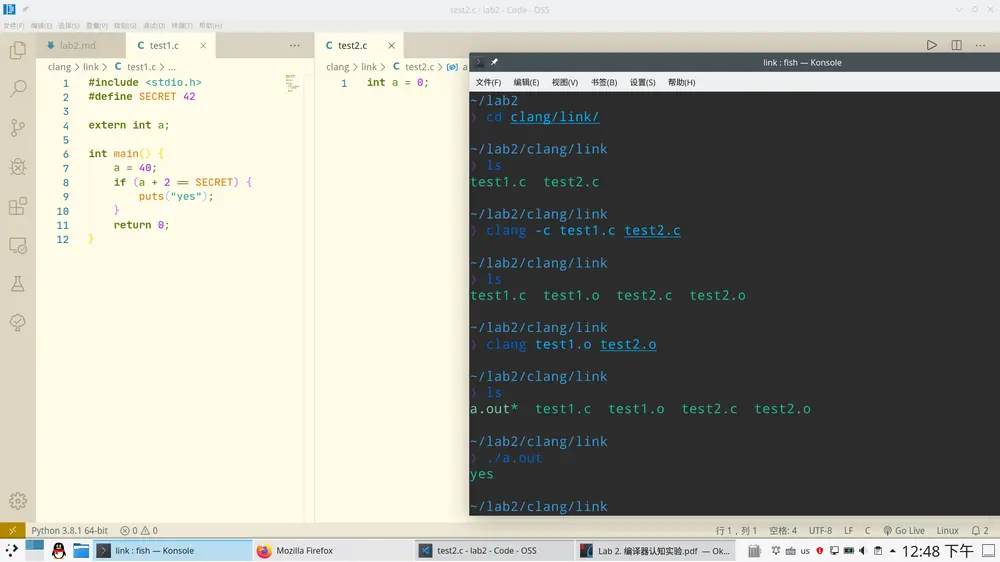
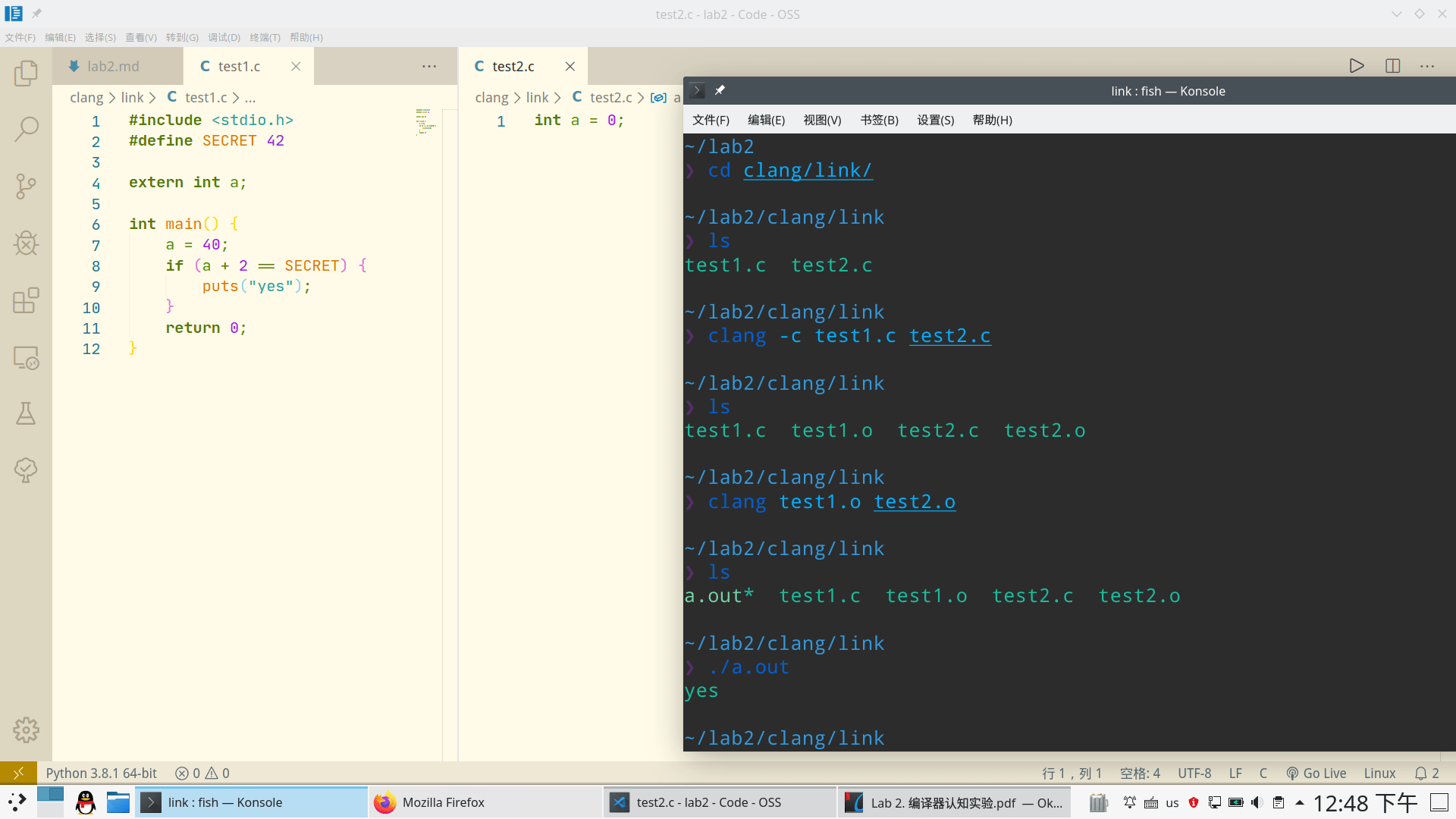
我把test.c拆成了test1.c和test2.c
test2.c
int a = 0;test1.c
#include <stdio.h> #define SECRET 42 extern int a; int main() { a = 40; if (a + 2 == SECRET) { puts("yes"); } return 0; }就是2里声明了a变量,1里拿来用了。虽然简单,但的确是两个源码为一个程序服务。
编译成目标文件,链接目标文件为一个可执行文件的命令
gcc -c test1.c test2.c gcc test1.o test2.o最后生成的a.out运行正常,输出了yes
查看预处理结果:gcc -E hello.c -o hello.i
# 1 "test.c" # 1 "<built-in>" # 1 "<命令行>" # 31 "<命令行>" # 1 "/usr/include/stdc-predef.h" 1 3 4 # 32 "<命令行>" 2 # 1 "test.c" # 1 "/usr/include/stdio.h" 1 3 4 # 27 "/usr/include/stdio.h" 3 4 # 1 "/usr/include/bits/libc-header-start.h" 1 3 4 # 33 "/usr/include/bits/libc-header-start.h" 3 4 # 1 "/usr/include/features.h" 1 3 4 # 450 "/usr/include/features.h" 3 4 # 1 "/usr/include/sys/cdefs.h" 1 3 4 # 460 "/usr/include/sys/cdefs.h" 3 4 # 1 "/usr/include/bits/wordsize.h" 1 3 4 # 461 "/usr/include/sys/cdefs.h" 2 3 4 # 1 "/usr/include/bits/long-double.h" 1 3 4 # 462 "/usr/include/sys/cdefs.h" 2 3 4 # 451 "/usr/include/features.h" 2 3 4 # 474 "/usr/include/features.h" 3 4 # 1 "/usr/include/gnu/stubs.h" 1 3 4 # 10 "/usr/include/gnu/stubs.h" 3 4 # 1 "/usr/include/gnu/stubs-64.h" 1 3 4 # 11 "/usr/include/gnu/stubs.h" 2 3 4 # 475 "/usr/include/features.h" 2 3 4 # 34 "/usr/include/bits/libc-header-start.h" 2 3 4 # 28 "/usr/include/stdio.h" 2 3 4看来记录了文件名,读取了相关的头文件
查看语法分析树:gcc -fdump-tree-all hello.c
老师说推荐分析.original、.gimple、.lower、.cfg文件,所以用如下命令:
gcc -fdump-tree-{original, gimple, lower, cfg} test.c根据文档,生成文件的数字是“遍”(pass)数,数字后的t代表tree,最后的扩展名是遍的名字。所以我们可以知道文件生成的顺序。
test.c
#include <stdio.h> #define SECRET 42 int main() { int a = 40; if (a + 2 == SECRET) { puts("yes"); } return 0; }生成的中间“树”:
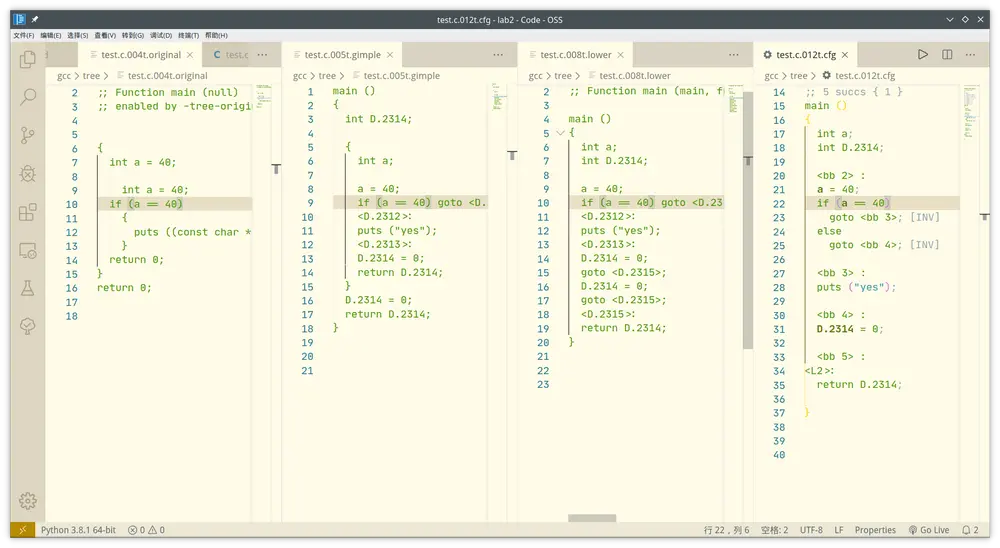
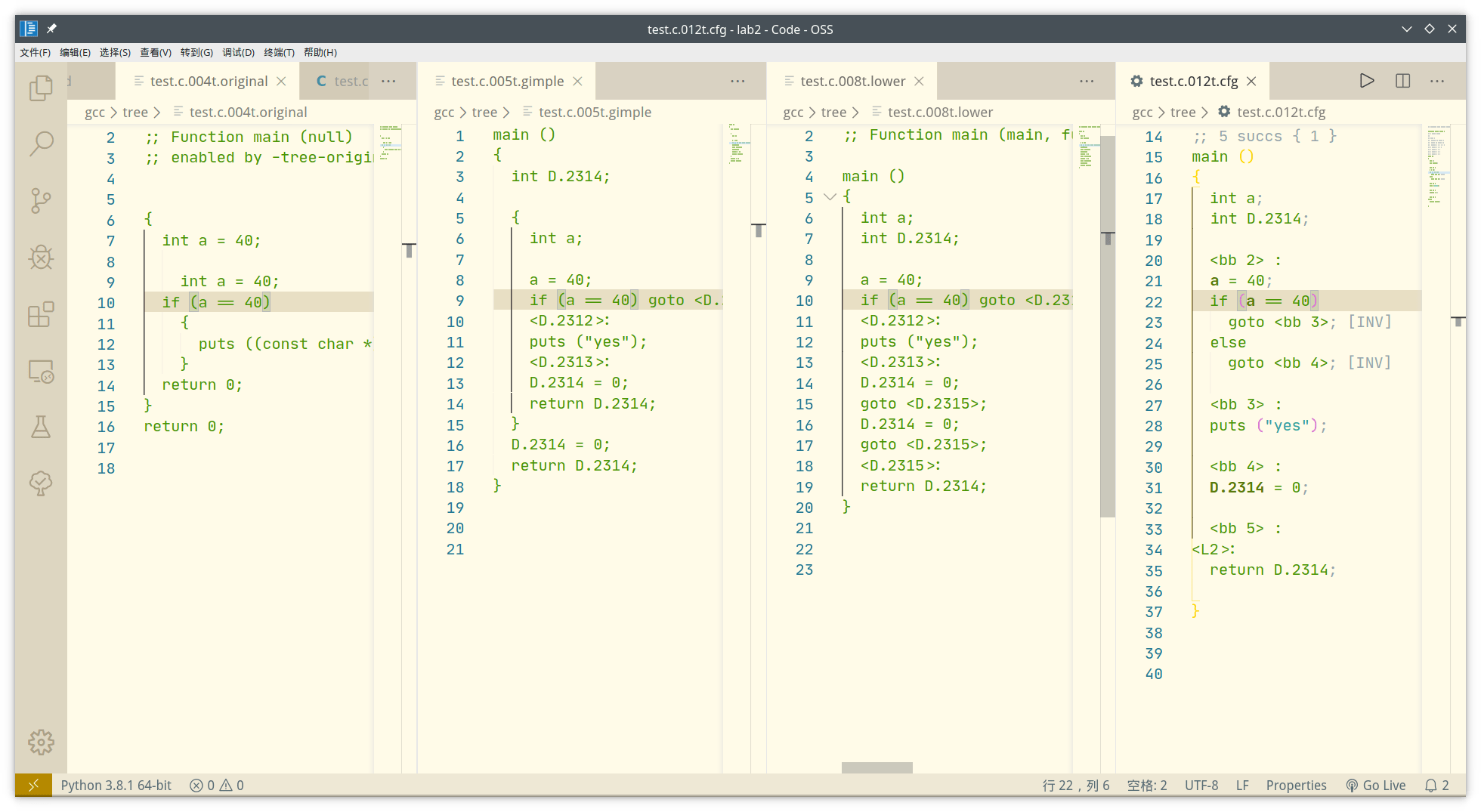
我们对比if那句,在original里基本没有改变,只是把大括号也往里缩进了。
到gimple里把if通过后的代码块用goto和标记改写了:
if (a == 40) goto <D.2312>; else goto <D.2313>; <D.2312>: puts ("yes"); <D.2313>:从gimple到lower,if这句没有改变。有改变的是lower里消除了gimple里多嵌套的一对花括号和return语句。
到cfg里改变的主要是goto的标记:之前和gimple的中间变量一样,是“<D.几几几几>”的形式,现在是“<bb 几>”(中间变量仍然是D开头形式)
if (a == 40) goto <bb 3>; [INV] else goto <bb 4>; [INV] <bb 3> : puts ("yes"); <bb 4> : D.2314 = 0;我感觉tree主要做的事就是用goto来表示流程。
查看中间代码生成结果:Code generation result: gcc -fdump-rtl-all hello.c
这RTL根本就是Lisp!打开Lisp的高亮,看起来舒服多了。
test.c与上一个实验相同,我们和.expand对比if语句(因为后面优化了怕差异太大)
RTL基本上是汇编+无限多寄存器,所以汇编的一些指令和RTL指令很相似,比如跳转:RTL里是
jump_insn。expand里总共只有一句跳转,所以if一定是它(其实"test.c":6:8也指明了,这一段是第6行):
(jump_insn 7 6 8 2 (set (pc) (if_then_else (ne (reg:CCZ 17 flags) (const_int 0 [0])) (label_ref 11) (pc))) "test.c":6:8 -1 (nil) -> 11)这句话相当于
pc = r17 != 0? label(11): pc所以说上一句肯定是把test.c里的判断结果放到了r17里:
(insn 6 5 7 2 (set (reg:CCZ 17 flags) (compare:CCZ (mem/c:SI (plus:DI (reg/f:DI 77 virtual-stack-vars) (const_int -4 [0xfffffffffffffffc])) [1 a+0 S4 A32]) (const_int 40 [0x28]))) "test.c":6:8 -1 (nil))mem/c……一直到A32那句可以理解成“当前栈顶-4”——也就是main函数的栈顶-4——得到变量a
compare拿a和40比,并且把结果通过set放到r17里。compare应该对应汇编的cmp,所以相等是0,不等非0。
回到jump_insn,如果r17不为0,就说明a不等于40(对应test.c的a+2!=42),跳到label(11):
(code_label 11 10 12 5 2 (nil) [1 uses])如果等于40,就会顺序执行,接下来是一句call语句,这和汇编也很像:
(call_insn 10 9 11 4 (set (reg:SI 0 ax) (call (mem:QI (symbol_ref:DI ("puts") [flags 0x41] <function_decl 0x7fbd3fe12200 puts>) [0 __builtin_puts S1 A8]) (const_int 0 [0]))) "test.c":7:9 -1 (nil) (expr_list:DI (use (reg:DI 5 di)) (nil)))很容易看清是从符号表(PLT)里找puts去调用
这一段执行之后就到了label(11)了。
用前面.cfg的风格写一下这段RTL的伪代码:
if (compare (a, 40) != 0) goto label11; else NULL call ("puts"); label11: ……查看生成的目标代码(汇编代码):gcc –S hello.c –o hello.
看了这么长可能已经忘了一直在对比的源码了,这里我把它再贴出来:
if (a + 2 == SECRET) { puts("yes"); } return 0;汇编没有RTL那一堆括号清爽多了,if语句对应的就是这几句:
cmpl $40, -4(%rbp) ; 对应RTL里一长串virtual-stack-vars……-4 jne .L2 ; 对应RTL里的jump_insn,gimple里的goto,实际程序的if leaq .LC0(%rip), %rdi ; 把字符串地址放到寄存器里 call puts@PLT ; 调用puts函数(从PLT里找),参数就是上一步的rdi .L2: ; 这就是a != 40跳转的地方,源程序就return 0了 movl $0, %eax ; 准备好0 leave .cfi_def_cfa 7, 8 ret ; 把0 return出去 .cfi_endproc ; 程序到此结束
LLVM运行结果分析
查看编译器的版本
❯ clang --version clang version 9.0.1 Target: x86_64-pc-linux-gnu Thread model: posix InstalledDir: /usr/bin使用编译器编译单个文件
clang test.c使用编译器编译链接多个文件
还是GCC时那两个文件,一样的操作,只不过把GCC换成Clang
查看编译流程和阶段:clang -ccc-print-phases test.c -c
❯ clang -ccc-print-phases test.c -c 0: input, "test.c", c 1: preprocessor, {0}, cpp-output 2: compiler, {1}, ir 3: backend, {2}, assembler 4: assembler, {3}, object查看词法分析结果:clang test.c -Xclang -dump-tokens -c
打印出来很长,因为它把stdio的代码也进行词法分析了,这里只截取test.c的:
int 'int' [StartOfLine] Loc=<test.c:4:1> identifier 'main' [LeadingSpace] Loc=<test.c:4:5> l_paren '(' Loc=<test.c:4:9> r_paren ')' Loc=<test.c:4:10> l_brace '{' [LeadingSpace] Loc=<test.c:4:12> int 'int' [StartOfLine] [LeadingSpace] Loc=<test.c:5:5> identifier 'a' [LeadingSpace] Loc=<test.c:5:9> equal '=' [LeadingSpace] Loc=<test.c:5:11> numeric_constant '40' [LeadingSpace] Loc=<test.c:5:13> semi ';' Loc=<test.c:5:15> if 'if' [StartOfLine] [LeadingSpace] Loc=<test.c:6:5> l_paren '(' [LeadingSpace] Loc=<test.c:6:8> identifier 'a' Loc=<test.c:6:9> plus '+' [LeadingSpace] Loc=<test.c:6:11> numeric_constant '2' [LeadingSpace] Loc=<test.c:6:13> equalequal '==' [LeadingSpace] Loc=<test.c:6:15> numeric_constant '42' [LeadingSpace] Loc=<test.c:6:18 <Spelling=test.c:2:16>> r_paren ')' Loc=<test.c:6:24> l_brace '{' [LeadingSpace] Loc=<test.c:6:26> identifier 'puts' [StartOfLine] [LeadingSpace] Loc=<test.c:7:9> l_paren '(' Loc=<test.c:7:13> string_literal '"yes"' Loc=<test.c:7:14> r_paren ')' Loc=<test.c:7:19> semi ';' Loc=<test.c:7:20> r_brace '}' [StartOfLine] [LeadingSpace] Loc=<test.c:8:5> return 'return' [StartOfLine] [LeadingSpace] Loc=<test.c:9:5> numeric_constant '0' [LeadingSpace] Loc=<test.c:9:12> semi ';' Loc=<test.c:9:13> r_brace '}' [StartOfLine] Loc=<test.c:10:1> eof '' Loc=<test.c:10:2>看得出是:类型+实际字符串+无用字符+文件中位置的格式
if那句就是:
if 'if' [StartOfLine] [LeadingSpace] Loc=<test.c:6:5> l_paren '(' [LeadingSpace] Loc=<test.c:6:8> identifier 'a' Loc=<test.c:6:9> plus '+' [LeadingSpace] Loc=<test.c:6:11> numeric_constant '2' [LeadingSpace] Loc=<test.c:6:13> equalequal '==' [LeadingSpace] Loc=<test.c:6:15> numeric_constant '42' [LeadingSpace] Loc=<test.c:6:18 <Spelling=test.c:2:16>> r_paren ')' Loc=<test.c:6:24>这比GCC莫名其妙的“tree”更贴近教材。
查看词法分析结果 2:clang test.c -Xclang -dump-raw-tokens -c
hash '#' [StartOfLine] Loc=<test.c:1:1> raw_identifier 'include' Loc=<test.c:1:2> unknown ' ' Loc=<test.c:1:9> less '<' Loc=<test.c:1:10> raw_identifier 'stdio' Loc=<test.c:1:11> period '.' Loc=<test.c:1:16> raw_identifier 'h' Loc=<test.c:1:17> greater '>' Loc=<test.c:1:18> unknown ' ' Loc=<test.c:1:19> hash '#' [StartOfLine] Loc=<test.c:2:1> raw_identifier 'define' Loc=<test.c:2:2> unknown ' ' Loc=<test.c:2:8> raw_identifier 'SECRET' Loc=<test.c:2:9> unknown ' ' Loc=<test.c:2:15> numeric_constant '42' Loc=<test.c:2:16> unknown ' ' Loc=<test.c:2:18> raw_identifier 'int' [StartOfLine] Loc=<test.c:4:1> unknown ' ' Loc=<test.c:4:4> raw_identifier 'main' Loc=<test.c:4:5> l_paren '(' Loc=<test.c:4:9> r_paren ')' Loc=<test.c:4:10> unknown ' ' Loc=<test.c:4:11> l_brace '{' Loc=<test.c:4:12> unknown ' ' Loc=<test.c:4:13> raw_identifier 'int' [StartOfLine] Loc=<test.c:5:5> unknown ' ' Loc=<test.c:5:8> raw_identifier 'a' Loc=<test.c:5:9> unknown ' ' Loc=<test.c:5:10> equal '=' Loc=<test.c:5:11> unknown ' ' Loc=<test.c:5:12> numeric_constant '40' Loc=<test.c:5:13> semi ';' Loc=<test.c:5:15> unknown ' ' Loc=<test.c:5:16> raw_identifier 'if' [StartOfLine] Loc=<test.c:6:5> unknown ' ' Loc=<test.c:6:7> l_paren '(' Loc=<test.c:6:8> raw_identifier 'a' Loc=<test.c:6:9> unknown ' ' Loc=<test.c:6:10> plus '+' Loc=<test.c:6:11> unknown ' ' Loc=<test.c:6:12> numeric_constant '2' Loc=<test.c:6:13> unknown ' ' Loc=<test.c:6:14> equalequal '==' Loc=<test.c:6:15> unknown ' ' Loc=<test.c:6:17> raw_identifier 'SECRET' Loc=<test.c:6:18> r_paren ')' Loc=<test.c:6:24> unknown ' ' Loc=<test.c:6:25> l_brace '{' Loc=<test.c:6:26> unknown ' ' Loc=<test.c:6:27> raw_identifier 'puts' [StartOfLine] Loc=<test.c:7:9> l_paren '(' Loc=<test.c:7:13> string_literal '"yes"' Loc=<test.c:7:14> r_paren ')' Loc=<test.c:7:19> semi ';' Loc=<test.c:7:20> unknown ' ' Loc=<test.c:7:21> r_brace '}' [StartOfLine] Loc=<test.c:8:5> unknown ' ' Loc=<test.c:8:6> raw_identifier 'return' [StartOfLine] Loc=<test.c:9:5> unknown ' ' Loc=<test.c:9:11> numeric_constant '0' Loc=<test.c:9:12> semi ';' Loc=<test.c:9:13> unknown ' ' Loc=<test.c:9:14> r_brace '}' [StartOfLine] Loc=<test.c:10:1>首先raw-tokens不会去引用的库里读代码。
其次分析出来的类型也只是字符串本身,没经过归类的属性。比如将空格分类给“unknown”,上一个实验里它就是“[LeadingSpace]”,还有include的尖括号,这里也直接分析成大于小于号
if那句和上面类似,只不过叫成了“raw_identifier 'if'”
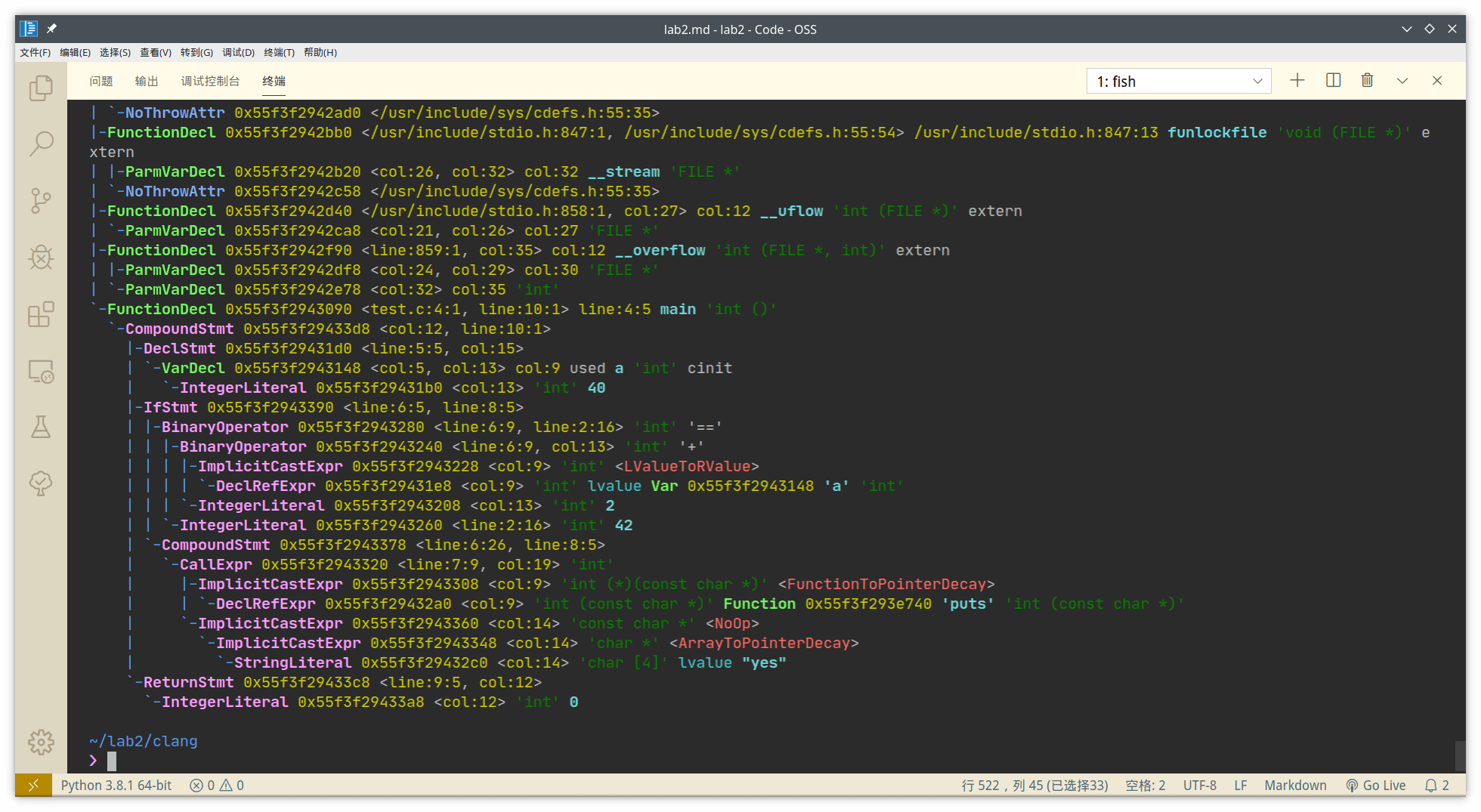
查看语义分析结果:clang test.c -Xclang -ast-dump -c
很好看,是彩色的:
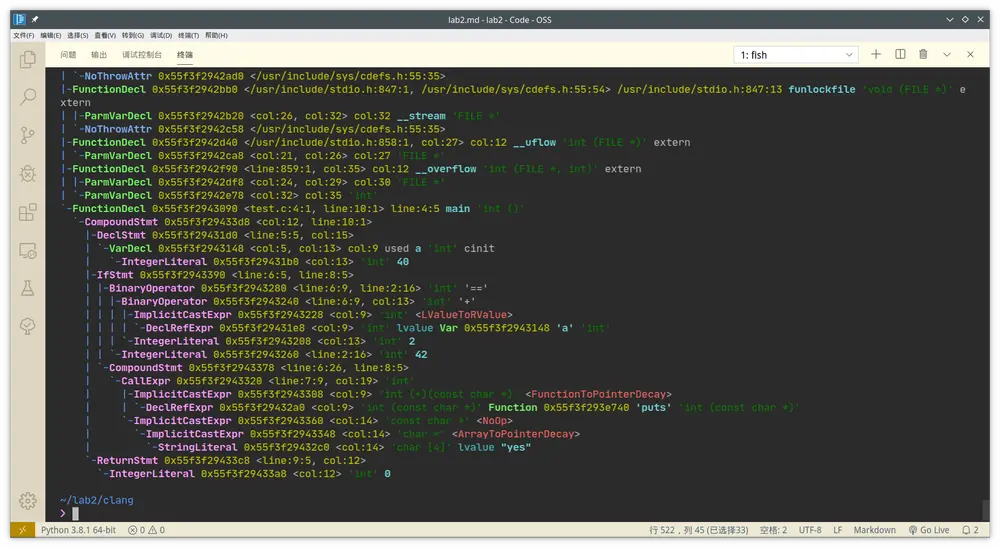
同样这里只取main本身的
此时从token stream里分析出了具体含义,比如把
int 'int' identifier 'main' l_paren '(' r_paren ')' l_brace '{' …… r_brace '}'转换成了FunctionDecl……main……,而且是用树的形式打印的,作用域什么的一目了然(再瞧瞧GCC那所谓的“tree”,里头竟然全是用goto分割树枝的代码)
`-FunctionDecl 0x5607f994d090 <test.c:4:1, line:10:1> line:4:5 main 'int ()' `-CompoundStmt 0x5607f994d3d8 <col:12, line:10:1> |-DeclStmt 0x5607f994d1d0 <line:5:5, col:15> | `-VarDecl 0x5607f994d148 <col:5, col:13> col:9 used a 'int' cinit | `-IntegerLiteral 0x5607f994d1b0 <col:13> 'int' 40 |-IfStmt 0x5607f994d390 <line:6:5, line:8:5> | |-BinaryOperator 0x5607f994d280 <line:6:9, line:2:16> 'int' '==' | | |-BinaryOperator 0x5607f994d240 <line:6:9, col:13> 'int' '+' | | | |-ImplicitCastExpr 0x5607f994d228 <col:9> 'int' <LValueToRValue> | | | | `-DeclRefExpr 0x5607f994d1e8 <col:9> 'int' lvalue Var 0x5607f994d148 'a' 'int' | | | `-IntegerLiteral 0x5607f994d208 <col:13> 'int' 2 | | `-IntegerLiteral 0x5607f994d260 <line:2:16> 'int' 42 | `-CompoundStmt 0x5607f994d378 <line:6:26, line:8:5> | `-CallExpr 0x5607f994d320 <line:7:9, col:19> 'int' | |-ImplicitCastExpr 0x5607f994d308 <col:9> 'int (*)(const char *)' <FunctionToPointerDecay> | | `-DeclRefExpr 0x5607f994d2a0 <col:9> 'int (const char *)' Function 0x5607f9948740 'puts' 'int (const char *)' | `-ImplicitCastExpr 0x5607f994d360 <col:14> 'const char *' <NoOp> | `-ImplicitCastExpr 0x5607f994d348 <col:14> 'char *' <ArrayToPointerDecay> | `-StringLiteral 0x5607f994d2c0 <col:14> 'char [4]' lvalue "yes" `-ReturnStmt 0x5607f994d3c8 <line:9:5, col:12> `-IntegerLiteral 0x5607f994d3a8 <col:12> 'int' 0显然我们一直在对比的if就是
IfStmt以及它下面那些Operator、Expr、Stmt、Literal什么的查看编译优化的结果:clang test.c -S -mllvm -print-after-all
控制台输出了一大堆中间代码,而且是向stderr输出的,为什么不是stdout???
前些个pass的输出还比较可读,我选了第一个和源码比较
*** IR Dump After Instrument function entry/exit with calls to e.g. mcount() (pre inlining) *** ; Function Attrs: noinline nounwind optnone sspstrong uwtable define dso_local i32 @main() #0 { %1 = alloca i32, align 4 %2 = alloca i32, align 4 store i32 0, i32* %1, align 4 store i32 40, i32* %2, align 4 %3 = load i32, i32* %2, align 4 %4 = add nsw i32 %3, 2 %5 = icmp eq i32 %4, 42 br i1 %5, label %6, label %8 6: ; preds = %0 %7 = call i32 @puts(i8* getelementptr inbounds ([4 x i8], [4 x i8]* @.str, i64 0, i64 0)) br label %8 8: ; preds = %6, %0 ret i32 0 }这应该是LLVM IR,很明显
define dso_local i32 @main()这一句是定义返回值是int32的main函数。LLVM IR里一切数据都要指定类型与大小,就比如说这些i32;变量用“%”开头,命令都是直接写,比如“store”
main里前四句是申请两个i32的内存,一个放0一个放40(变量a)
%3 = load i32, i32* %2, align 4把a读入(这个store、load像RISC诶)%4 = add nsw i32 %3, 2给 a 加 2,然后%5 = icmp eq i32 %4, 42比较结果等不等于42(看来LLVM IR并没有明确的寄存器,都是通过=赋值的,变成寄存器应该是之后才优化)br i1 %5, label %6, label %8就是if-else了:true就goto到label6,也就是call puts那句;否则是label8,直接return 0。到最后就变成对寄存器操作了:
# *** IR Dump After Check CFA info and insert CFI instructions if needed ***: # Machine code for function main: NoPHIs, TracksLiveness, NoVRegs Frame Objects: fi#-1: size=8, align=16, fixed, at location [SP-8] fi#0: size=4, align=4, at location [SP-12] fi#1: size=4, align=4, at location [SP-16] bb.0 (%ir-block.0): successors: %bb.2, %bb.1 frame-setup PUSH64r killed $rbp, implicit-def $rsp, implicit $rsp CFI_INSTRUCTION def_cfa_offset 16 CFI_INSTRUCTION offset $rbp, -16 $rbp = frame-setup MOV64rr $rsp CFI_INSTRUCTION def_cfa_register $rbp $rsp = frame-setup SUB64ri8 $rsp(tied-def 0), 16, implicit-def dead $eflags MOV32mi $rbp, 1, $noreg, -4, $noreg, 0 :: (store 4 into %ir.1) MOV32mi $rbp, 1, $noreg, -8, $noreg, 40 :: (store 4 into %ir.2) renamable $eax = MOV32rm $rbp, 1, $noreg, -8, $noreg :: (load 4 from %ir.2) renamable $eax = ADD32ri8 renamable $eax(tied-def 0), 2, implicit-def $eflags CMP32ri8 killed renamable $eax, 42, implicit-def $eflags JCC_1 %bb.2, 5, implicit $eflags bb.1 (%ir-block.6): ; predecessors: %bb.0 successors: %bb.2 renamable $rdi = LEA64r $rip, 1, $noreg, @.str, $noreg CALL64pcrel32 target-flags(x86-plt) @puts, <regmask $bh $bl $bp $bph $bpl $bx $ebp $ebx $hbp $hbx $rbp $rbx $r12 $r13 $r14 $r15 $r12b $r13b $r14b $r15b $r12bh $r13bh $r14bh $r15bh $r12d $r13d $r14d $r15d $r12w $r13w $r14w $r15w $r12wh and 3 more...>, implicit $rsp, implicit $ssp, implicit killed $rdi, implicit-def $eax bb.2 (%ir-block.8): ; predecessors: %bb.0, %bb.1 renamable $eax = XOR32rr undef $eax(tied-def 0), undef $eax, implicit-def $eflags $rsp = frame-destroy ADD64ri8 $rsp(tied-def 0), 16, implicit-def dead $eflags $rbp = frame-destroy POP64r implicit-def $rsp, implicit $rsp CFI_INSTRUCTION def_cfa $rsp, 8 RETQ implicit killed $eax # End machine code for function main.可以看到$rbp呀,$eax呀之类的寄存器出现,另外括号里有“%ir”的也像注释一样告诉你这对应IR的哪一句,比如
MOV32mi $rbp, 1, $noreg, -8, $noreg, 40 :: (store 4 into %ir.2)就是store i32 40, i32* %2, align 4把40放进第二个变量里。CMP32ri8 killed renamable $eax, 42, implicit-def $eflags是比较源码里的a和42,下一句JCC_1就是跳转(Jump Condition Code 1?)不跳转的话会执行
CALL64pcrel32……调用puts;跳转的话就到bb.2(也写了,对应IR里的label8)退栈(frame-destroy),返回。这个实验说是叫“查看编译优化的结果”,但其实到最后都还是判断a+2==42,GCC一上来到original就是判断a==40了。不过这也是因为测试程序太短了,所以出现的可优化特例没有被优化吧。
查看生成的目标代码结果:Target code generation:clang -S test.c
其实上一步就生成了汇编代码了,只不过这个命令不会往控制台打印很多东西。
生成的汇编文件中与if有关的是这一段:
movl $40, -8(%rbp) ; 很奇怪,Clang是用基址寄存器定位变量的 movl -8(%rbp), %eax ; 把a放到eax里 addl $2, %eax ; 给a加2 cmpl $42, %eax ; a和42比大小——这里GCC从**一开始**就优化掉了,直接跳过+2和40比大小 jne .LBB0_2 ; if语句来啦 # %bb.1: leaq .L.str(%rip), %rdi ; 把字符串放到rdi callq puts@PLT ; 调用puts .LBB0_2: xorl %eax, %eax ; 清零eax,GCC用的是mov 0 addq $16, %rsp popq %rbp ; 这两句对应GCC的leave .cfi_def_cfa %rsp, 8 retq
GCC与LLVM对比分析
CPU是英特尔i5-7200U,4核2.5GHz,4个32KB L1 Cache,两个256KB L2 Cache,一个 3M L3 Cache。内存16GB。
我用Python生成了1000001个0-32767的随机整数做输入列表,通过cat input.txt | ./a.out输入,程序内部记录排序函数的时间。每种优化程度计时6次取平均。
代码是lab1的未调优快排,表格单位是秒
| O0 | O1 | O2 | O3 | |
|---|---|---|---|---|
| GCC | 0.211604 | 0.102269 | 0.083705 | 0.087721 |
| Clang | 0.198786 | 0.101447 | 0.070781 | 0.070321 |
可以看到不管何种程度的优化,这两种编译器编译出的程序速度都很接近,只不过Clang一直比GCC快
而且只有最初的优化消减的时间多(O0到O1有0.1秒,O1到O2只有0.02秒),奇怪的是GCC的O3比O2还慢,是它优化太多把自己绕晕了?
实验心得体会
两个编译器都是“前后端分离”的:前段吐出语言无关、平台无关的中间代码,后端把中间代码翻译成汇编、机器码。
还有两个编译器都有很多pass,我原以为最多扫三遍就够了,工业级编译器真是不可小觑。clang -print-after-all的输出有37个after,大概有37个pass吧,GCC更狠,到dfinish有318个pass。我说C编译怎么那么慢呢,听说go很快,应该没多少pass吧。
对于中间代码来说,Clang比GCC更可读:Clang的IR类似RISC汇编,一条一条的简短但信息量足(指区分类型,变量、指令、寄存器的前缀命名),对应到GCC每一句都是好几行罗列好多奇怪数字的Lisp RTL。而且LLVM IR有变量的概念,GCC的RTL取一个变量都要通过栈顶加常量来获取——这一段就要两行+一万个括号。
而且Clang也更贴近教科书,或者说条理更清晰;GCC像是没怎么设计,总之能跑能用就得了的程序:对于语法树,Clang真的是以树形图打印的,GCC就是一团代码充斥着goto;中间代码,Clang好歹能看,GCC就像拿来Lisp写了一堆宏/函数发现能用就接着用了。
我以后写C/C++都会尽量用Clang了,这次实验GCC给我的印象太差了:又慢又混乱。Chrome在所有平台上都是用Clang编译的。
另外虽然我可能不会接触,但如果要二次开发的话,Clang是更好的选择,因为中间代码清爽许多。